How Kubernetes violates the Principle of Least Surprise when used with PROXY Protocol on Hetzner Load Balancers
by Peter Stolz, Alexander Fink
Kubernetes is a complex tool allowing you to dynamically scale your microservices, renew ssl certificates, seamlessly upgrade services and many more. But with that many features comes great complexity. In this post we explore weird networking issues when we migrated the Hetzner LoadBalancer to use the PROXY protocol and their solutions.
It all started with the simple idea to deploy rate limiting on sensitive endpoints like /login. The only problem was that the source IP inside the pod was always in the 10.0.0.0/8 subnet. Hence the service only observes local IP addresses instead of the actual remote one. This has the drawback that rate limits are now enforced upon all users combined and not on an IP basis, enabling trivial Denial of Service.
The typical solution for an HTTP service behind a reverse proxy is the Forwarded or X-Forwarded-For header. The problem is that this did not work for some reason. Therefore we wanted to use the PROXY protocol, which basically adds a plaintext header to the beginning of a TCP connection as shown below:
PROXY TCP4 192.168.0.1 192.168.0.11 56324 443\r\n
GET / HTTP/1.1\r\n
Host: 192.168.0.11\r\n
\r\n
PROXY PROTOCOL SRC_IP DST_IP SRC_PORT DST_PORT\r\n
This has the benefit that we can use any TCP protocol and still know the real origin.
After reading a blog post on the Hetzner community forums, the solution seemed trivial. Simply add
data:
compute-full-forwarded-for: "true"
use-forwarded-headers: "true"
use-proxy-protocol: "true"
to your ingress-nginx-controller. This tells Nginx to expect the PROXY Protocol requests and add the full-forwarded-for header to requests. Finally, enable the PROXY protocol on the Hetzner web interface, and you are good to go, they said.
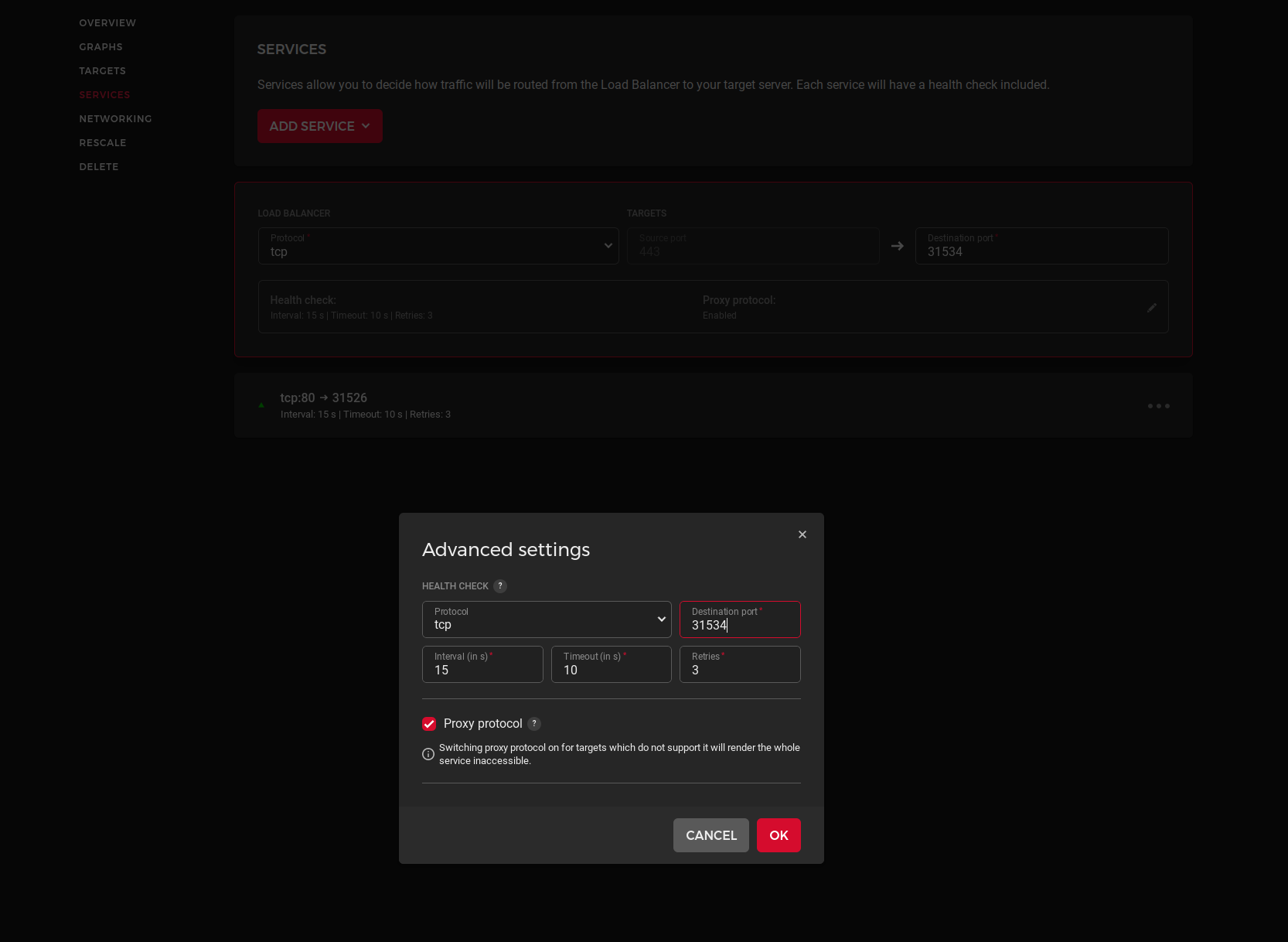
For external connections, this worked fine, but for cluster, internal communications, nothing worked anymore.
Our monitoring systems were reporting problems from almost all microservices.
Retrieving the Kubernetes logs, Nginx showed that weird error message for cluster internal requests:
2022/09/07 14:06:22 [error] 11256#11256: *198160338 broken header: "
To play around with it, we manually crafted small HTTP requests and send them over with Netcat
echo -ne 'GET /?testtest HTTP/1.1\r
\r\n' | nc auth.bitahoy.cloud 80 -v
Connection to auth.bitahoy.cloud 80 port [tcp/http] succeeded!
We established a TCP connection but got no response back at all.
The next step was to send a request with a PROXY header in case our traffic misses the load balancer.
echo -ne 'PROXY TCP4 8.8.8.8 167.233.15.218 32808 80\r
GET /?testtest HTTP/1.1\r
\r\n' | nc auth.bitahoy.cloud 80
HTTP/1.1 400 Bad Request
Date: Fri, 09 Sep 2022 07:56:52 GMT
Content-Type: text/html
Content-Length: 150
Connection: close
<html>
<head><title>400 Bad Request</title></head>
<body>
<center><h1>400 Bad Request</h1></center>
<hr><center>nginx</center>
</body>
</html>
8.8.8.8 - - [07/Sep/2022:15:43:48 +0000] "GET /testtest HTTP/1.1" 400 150 "-" "-" 55 0.000 [] [] - - - - 70361d95651a725a4b7227b5b5ccd564
Okay, this confirms that our traffic does not get the PROXY header appended. We can even spoof our source IP here, but the 400 Bad Request is still weird.
After some time, we realized that the Host header needs to be set
echo -ne 'PROXY TCP4 8.8.8.8 167.233.15.218 32808 80\r
GET /?testtest HTTP/1.1\r
\t\t\t Host: auth.bitahoy.cloud\r
\r\n' | nc auth.bitahoy.cloud 80 -v
Connection to auth.bitahoy.cloud 80 port [tcp/http] succeeded!
HTTP/1.1 308 Permanent Redirect
Date: Fri, 09 Sep 2022 08:06:12 GMT
Content-Type: text/html
Content-Length: 164
Connection: keep-alive
Location: https://auth.bitahoy.cloud/?testtest
Access-Control-Allow-Credentials: true
<html>
<head><title>308 Permanent Redirect</title></head>
<body>
<center><h1>308 Permanent Redirect</h1></center>
<hr><center>nginx</center>
</body>
</html>
Using ksniff, we captured incoming traffic from the ingress Nginx server, which confirmed our suspicion. Only requests that were sent within the cluster were missing the PROXY header.
kubectl sniff -n ingress-nginx ingress-nginx-controller-6f6699b4b7-wh6dx -p -o nginx.pcap
There we go. We have a case, and let’s investigate if the traffic, for some reason, is not routed through the external load balancer.
Our initial suspicion was that there are 2 interfaces for the load balancer.
One interface with the external IP and one with the internal Kubernetes VMs network. And we assumed the traffic from the VMs network is not processed correctly.
To confirm this, we looked at the difference in routes from a pod and another unrelated Hetzner machine.
The route from the Hetzner machine:
root@PlainWireGuard ~# traceroute auth.bitahoy.cloud
traceroute to auth.bitahoy.cloud (167.233.15.218), 30 hops max, 60 byte packets
1 _gateway (172.31.1.1) 11.867 ms 11.744 ms 11.779 ms
2 13868.your-cloud.host (116.203.163.139) 0.814 ms 0.772 ms 0.749 ms
3 * * *
4 static.88-198-249-245.clients.your-server.de (88.198.249.245) 1.212 ms static.88-198-249-241.clients.your-server.de (88.198.249.241) 1.350 ms 1.361 ms
5 spine14.cloud1.nbg1.hetzner.com (213.133.113.69) 1.235 ms spine11.cloud1.nbg1.hetzner.com (213.133.108.145) 1.333 ms spine14.cloud1.nbg1.hetzner.com (213.133.113.69) 1.570 ms
6 spine1.cloud1.nbg1.hetzner.com (213.133.108.162) 1.214 ms spine2.cloud1.nbg1.hetzner.com (213.133.112.198) 0.817 ms spine1.cloud1.nbg1.hetzner.com (213.133.112.194) 0.806 ms
7 * * *
8 static.254.65.201.195.clients.your-server.de (195.201.65.254) 0.409 ms 0.377 ms 0.320 ms
9 bitahoy.com (167.233.15.218) 0.336 ms 0.434 ms 0.401 ms
The route from the pod:
root@vpncontrol-backend-b696df648-2424b:/app# traceroute auth.bitahoy.cloud
traceroute to auth.bitahoy.cloud (167.233.15.218), 30 hops max, 60 byte packets
1 static.212.58.235.167.clients.your-server.de (167.235.58.212) 0.046 ms 0.021 ms 0.018 ms
2 172.31.1.1 (172.31.1.1) 6.339 ms 6.355 ms 6.278 ms
3 18442.your-cloud.host (168.119.216.144) 0.298 ms 0.285 ms 0.237 ms
4 * * *
5 static.153.28.46.78.clients.your-server.de (78.46.28.153) 0.877 ms 1.323 ms 1.319 ms
6 spine13.cloud1.nbg1.hetzner.com (213.133.114.1) 0.920 ms spine11.cloud1.nbg1.hetzner.com (85.10.250.73) 0.903 ms spine12.cloud1.nbg1.hetzner.com (85.10.246.125) 0.882 ms
7 spine1.cloud1.nbg1.hetzner.com (213.133.112.46) 9.174 ms spine2.cloud1.nbg1.hetzner.com (213.133.112.90) 2.524 ms spine2.cloud1.nbg1.hetzner.com (213.133.112.198) 2.495 ms
8 * * *
9 static.254.65.201.195.clients.your-server.de (195.201.65.254) 0.465 ms 0.410 ms 0.379 ms
10 ingress-nginx-controller.ingress-nginx.svc.cluster.local (167.233.15.218) 0.374 ms 0.388 ms 0.344 ms
What should have been suspicious is that the domain name of the external load balancer inside the cluster is ingress-nginx-controller.ingress-nginx.svc.cluster.local, which is the domain name of the kubernetes internal load balancer instead of the public bitahoy.com domain.
But as the routes look similar, it did not look like a routing problem. Both connections go through the same “external” Hetzner routers.
As we needed a temporary fix, there is a way to bypass the internal load balancer by using internal Kubernetes domains.
Therefore I can reach a service as SERVICENAME.NAMESPACE.svc.cluster.local
This is also more efficient and stable, as the services can reach each other even if the load of the ingress-nginx-controller is high.
However, fixing domain names in all our microservices was a solution that would take quite some time, so we were still looking to get this routing fixed.
After some googling the next day, we stumbled over a similar problem on the digital ocean forum, which lead us to their GitHub documentation:
Because of an existing limitation in upstream Kubernetes, pods cannot talk to other pods via the IP address of an external load-balancer set up through a
LoadBalancer-typed service. Kubernetes will cause the LB to be bypassed, potentially breaking workflows that expect TLS termination or proxy protocol handling to be applied consistently.
We confirmed that it was the same problem in our case with:
kubectl get services -n ingress-nginx
NAMESPACE NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
ingress-nginx service/ingress-nginx-controller LoadBalancer 10.101.119.157 167.233.15.218,192.168.0.7,2a01:4f8:1c1d:ffc::1 80:31526/TCP,443:31534/TCP 219d app.kubernetes.io/component=controller,app.kubernetes.io/instance=ingress-nginx,app.kubernetes.io/name=ingress-nginx
Looking at the possible annotations at hetzner. Adding the annotation load-balancer.hetzner.cloud/hostname: cluster.bitahoy.cloud with kubectl edit service ingress-nginx-controller -n ingress-nginx did the trick. Now it looks like:
kubectl get services -n ingress-nginx
NAMESPACE NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
ingress-nginx service/ingress-nginx-controller LoadBalancer 10.101.119.157 cluster.bitahoy.cloud 80:31526/TCP,443:31534/TCP 220d app.kubernetes.io/component=controller,app.kubernetes.io/instance=ingress-nginx,app.kubernetes.io/name=ingress-nginx
and requests finally work within the cluster.
Takeaway
Kubernetes is a gigantic beast with a lot of unique quirks. For optimization reasons, it reroutes requests to the external load balancer internally, which breaks communication if you rely on traffic modification from that load balancer.
Adding a domain name to a LoadBalancer typed service removes this routing optimization.
We are not the first who had problems with this issue, but the hetzner documentation does not directly mention this problem, so we decided to do a little writeup on how we debugged and solved Kubernetes cross-service communication with a load balancer that has PROXY protocol enabled with the hetzner load balancer.
tags: Kubernetes - Hetzner - Routing - Networking - Microservices - Debugging - LoadBalancer